Greenplum MapReduce规范
该规范描述了用于定义Greenplum MapReduce作业的文档格式和模式。
MapReduce是由Google开发的一种编程模型,用于在商用服务器阵列上处理和生成大型数据集。 Greenplum MapReduce允许熟悉MapReduce模型的程序员编写map和reduce函数,并将它们提交给Greenplum数据库并行引擎进行处理。
要使Greenplum能够处理MapReduce函数,请在文档中定义函数,然后将文档传递给Greenplum MapReduce程序gpmapreduce,以便由Greenplum数据库并行引擎执行。
Greenplum数据库系统分配输入数据,在一组机器上执行程序,处理机器故障,并管理所需的机器间通信。
关于gpmapreduce的信息请见Greenplum数据库工具指南。
Parent topic: Greenplum数据库参考指南
Greenplum MapReduce文档格式
本节介绍Greenplum MapReduce文档格式的一些基础知识,以帮助您开始创建自己的Greenplum MapReduce文档。 Greenplum使用YAML 1.1文档格式,然后实现自己的模式,以定义MapReduce作业的各个步骤。
所有Greenplum MapReduce文件必须首先声明它们正在使用的YAML规范的版本。
之后,三个破折号(---)表示文档的开头,三个点(...)表示文档的结尾而不启动新文档。
注释行以井号(#)为前缀。
可以在同一个文件中声明多个Greenplum MapReduce文档:
%YAML 1.1
---
# Begin Document 1
# ...
---
# Begin Document 2
# ...
在Greenplum MapReduce文档中,有三种基本类型的数据结构或节点:标量,序列和映射。
标量是由空格缩进的基本文本字符串。
如果您有跨越多行的标量输入,则前面的管道(|)表示文字样式,其中所有换行符都很重要。
或者,前一个尖括号(>)将单个换行符折叠到具有相同缩进级别的后续行的空格。
如果字符串包含具有保留含义的字符,则必须引用该字符串,或者必须使用反斜杠(\)转义特殊字符。
# Read each new line literally
somekey: | this value contains two lines
and each line is read literally
# Treat each new line as a space
anotherkey: >
this value contains two lines
but is treated as one continuous line
# This quoted string contains a special character
ThirdKey: "This is a string: not a mapping"
序列是列表,列表中的每个条目都在其自己的行上,用短划线和空格(- )表示。
或者,您可以将内联序列指定为方括号内的逗号分隔列表。
序列提供一组数据并为其提供订单。
将列表加载到Greenplum MapReduce程序时,将保留订单。
# list sequence
- this
- is
- a list
- with
- five scalar values
# inline sequence
[this, is, a list, with, five scalar values]
映射用于将数据值与称为键的标识符配对。
映射对每个key: value对使用冒号和空格(: ),或者也可以内联指定为花括号内的逗号分隔列表。
该密钥用作从映射中检索数据的索引。
# a mapping of items
title: War and Peace
author: Leo Tolstoy
date: 1865
# same mapping written inline
{ title: War and Peace, author: Leo Tolstoy, date: 1865}
密钥用于将元信息与每个节点相关联,并指定预期的节点类型(标量,序列或映射)。 有关Greenplum MapReduce程序所需的键,请参阅Greenplum MapReduce文档模式。
Greenplum MapReduce程序按顺序处理文档的节点,并使用缩进(空格)来确定文档层次结构和节点之间的关系。 使用空白区域非常重要。 不应仅将白色空间用于格式化目的,并且根本不应使用制表符。
Greenplum MapReduce文档模式
Greenplum MapReduce使用YAML文档框架并实现自己的YAML模式。 Greenplum MapReduce文档的基本结构是:
%YAML 1.1
---
[VERSION](#topic3__VERSION): 1.0.0.2
[DATABASE](#topic3__DATABASE): dbname
[USER](#topic3__USER): db_username
[HOST](#topic3__HOST): master_hostname
[PORT](#topic3__PORT): master_port
[DEFINE](#topic3__DEFINE):
- [INPUT](#topic3__INPUT):
[NAME](#topic3__NAME): input_name
[FILE](#topic3__FILE):
- hostname:/path/to/file
[GPFDIST](#topic3__GPFDIST):
- hostname:port/file_pattern
[TABLE](#topic3__TABLE): table_name
[QUERY](#topic3__QUERY): SELECT_statement
[EXEC](#topic3__EXEC): command_string
[COLUMNS](#topic3__COLUMNS):
- field_name data_type
[FORMAT](#topic3__FORMAT): TEXT | CSV
[DELIMITER](#topic3__DELIMITER): delimiter_character
[ESCAPE](#topic3__ESCAPE): escape_character
[NULL](#topic3__NULL): null_string
[QUOTE](#topic3__QUOTE): csv_quote_character
[ERROR_LIMIT](#topic3__ERROR_LIMIT): integer
[ENCODING](#topic3__ENCODING): database_encoding
- [OUTPUT](#topic3__OUTPUT):
[NAME](#topic3__OUTPUTNAME): output_name
[FILE](#topic3__OUTPUTFILE): file_path_on_client
[TABLE](#topic3__OUTPUTTABLE): table_name
[KEYS](#topic3__KEYS):
- column_name
[MODE](#topic3__MODE): REPLACE | APPEND
- [MAP](#topic3__MAP):
[NAME](#topic3__NAME): function_name
[FUNCTION](#topic3__FUNCTION): function_definition
[LANGUAGE](#topic3__LANGUAGE): perl | python | c
[LIBRARY](#topic3__LIBRARY): /path/filename.so
[PARAMETERS](#topic3__PARAMETERS):
- nametype
[RETURNS](#topic3__RETURNS):
- nametype
[OPTIMIZE](#topic3__OPTIMIZE): STRICT IMMUTABLE
[MODE](#topic3__MODE): SINGLE | MULTI
- [TRANSITION | CONSOLIDATE | FINALIZE](#topic3__TCF):
[NAME](#topic3__TCFNAME): function_name
[FUNCTION](#topic3__FUNCTION): function_definition
[LANGUAGE](#topic3__LANGUAGE): perl | python | c
[LIBRARY](#topic3__LIBRARY): /path/filename.so
[PARAMETERS](#topic3__PARAMETERS):
- nametype
[RETURNS](#topic3__RETURNS):
- nametype
[OPTIMIZE](#topic3__OPTIMIZE): STRICT IMMUTABLE
[MODE](#topic3__TCFMODE): SINGLE | MULTI
- [REDUCE](#topic3__REDUCE):
[NAME](#topic3__REDUCENAME): reduce_job_name
[TRANSITION](#topic3__TRANSITION): transition_function_name
[CONSOLIDATE](#topic3__CONSOLIDATE): consolidate_function_name
[FINALIZE](#topic3__FINALIZE): finalize_function_name
[INITIALIZE](#topic3__INITIALIZE): value
[KEYS](#topic3__REDUCEKEYS):
- key_name
- [TASK](#topic3__TASK):
[NAME](#topic3__TASKNAME): task_name
[SOURCE](#topic3__SOURCE): input_name
[MAP](#topic3__TASKMAP): map_function_name
[REDUCE](#topic3__REDUCE): reduce_function_name
[EXECUTE](#topic3__EXECUTE)
- [RUN](#topic3__RUN):
[SOURCE](#topic3__EXECUTESOURCE): input_or_task_name
[TARGET](#topic3__TARGET): output_name
[MAP](#topic3__EXECUTEMAP): map_function_name
[REDUCE](#topic3__EXECUTEREDUCE): reduce_function_name...
VERSION
必须。Greenplum MapReduce YAML规范的版本。当前版本为1.0.0.1。
DATABASE
可选。指定Greenplum中要连接的数据库。如果未指定,则默认为默认数据库或$PGDATABASE(如果已设置)。
USER
可选。指定要用于连接的数据库角色。
如果未指定,则默认为当前用户或$PGUSER(如果已设置)。
您必须是Greenplum超级用户才能运行用不受信任的Python和Perl编写的函数。
常规数据库用户可以运行用可信Perl编写的函数。
您还必须是数据库超级用户才能运行包含FILE,
GPFDIST和EXEC输入类型的MapReduce作业。
HOST
可选。指定Greenplum master主机名。如果未指定,则默认为localhost或$PGHOST(如果已设置)。
PORT
可选。指定Greenplum主端口。如果未指定,则默认为5432或$PGPORT(如果已设置)。
DEFINE
必须。此MapReduce文档的一系列定义。DEFINE部分必须至少有一个INPUT定义。
INPUT
必须。定义输入数据。每个MapReduce文档必须至少定义一个输入。
文档中允许多个输入定义,但每个输入定义只能指定其中一种访问类型:文件,gpfdist文件分发程序,数据库中的表,SQL命令或操作系统命令。
有关gpfdist的信息,请参阅Greenplum数据库实用程序指南。
NAME
此输入的名称。关于此MapReduce作业中其他对象的名称(例如map函数,task,reduce函数和输出名称),名称必须是唯一的。 此外,名称不能与数据库中的现有对象(例如表,函数或视图)冲突。
FILE
一个或多个输入文件的序列,格式为:seghostname:/path/to/filename。
您必须是Greenplum数据库超级用户才能使用FILE输入运行MapReduce作业。
该文件必须位于Greenplum segment主机上。
GPFDIST
一个或多个运行gpfdist文件分发程序的序列,格式为:hostname[:port]/file_pattern。
除非服务器配置参数服务器配置参数设置为on,
否则您必须是Greenplum数据库超级用户才能使用GPFDIST输入运行MapReduce作业。
TABLE
数据库中现有表的名称。
QUERY
要在数据库中运行的SQL SELECT命令。
EXEC
要在Greenplum segment主机上运行的操作系统命令。
默认情况下,该命令由系统中的所有segment实例运行。
例如,如果每个segment主机有四个segment实例,则该命令将在每个主机上运行四次。
您必须是Greenplum数据库超级用户才能使用EXEC输入运行MapReduce作业,
并且服务器配置参数服务器配置参数设置为on。
COLUMNS
可选。列指定为:column_name [``data_type``]。
如果未指定,则默认值为value text。
DELIMITER字符用于分隔两个数据值字段(列)。
行由换行符(0x0a)确定。
FORMAT
可选。指定数据的格式 - 分隔文本(TEXT)或逗号分隔值(CSV)格式。
如果未指定数据格式,则默认为TEXT。
DELIMITER
可选FILE,
GPFDIST和EXEC输入。
指定用于分隔数据值的单个字符。
默认值为TEXT模式下的制表符,CSV模式下为逗号。
分隔符字符只能出现在任意两个数据值字段之间。
不要在行的开头或结尾放置分隔符。
ESCAPE
对于FILE, GPFDIST和EXEC输入可选。
指定用于C转义序列的单个字符(例如\n,\t,\100等)以及转义可能以行或列分隔符形式取出的数据字符。
确保选择实际列数据中未使用的转义字符。
默认转义字符是文本格式文件的\(反斜杠)和csv格式文件的"(双引号),但是可以指定另一个字符来表示转义。
也可以通过指定禁用转义值'OFF'作为转义值。
这对于诸如文本格式的Web日志数据之类的数据非常有用,这些数据具有许多不打算转义的嵌入式反斜杠。
NULL
对于FILE, GPFDIST和EXEC输入可选。
指定表示空值的字符串。
默认值为TEXT格式的\N,以及CSV格式没有引号的空值。
如果您不想将空值与空字符串区分开来,即使在TEXT模式下,您可能更喜欢空字符串。
与此字符串匹配的任何输入数据项都将被视为空值。
QUOTE
对于FILE, GPFDIST和EXEC输入可选。
指定CSV格式文件的引用字符。
默认值为双引号(")。
在CSV格式的文件中,如果数据值字段包含任何逗号或嵌入的新行,则必须用双引号括起来。
包含双引号字符的字段必须用双引号括起来,并且嵌入双引号必须由一对连续的双引号表示。
始终正确打开和关闭引号以便正确解析数据行非常重要。
ERROR_LIMIT 如果输入行具有格式错误,则只要在输入处理期间未在任何Greenplum segment实例上达到错误限制计数,它们将被丢弃。 如果未达到错误限制,则将处理所有正常行并丢弃任何错误行。
ENCODING
用于数据的字符集编码。
指定字符串常量(例如'SQL_ASCII'),整数编码号或DEFAULT以使用默认客户端编码。
有关更多信息,请参阅字符集支持。
OUTPUT
可选。定义输出此MapReduce作业的格式化数据的位置。
如果未定义输出,则默认为STDOUT(客户端的标准输出)。
您可以将输出发送到客户端主机上的文件或数据库中的现有表。
NAME
此输出的名称。默认输出名称为STDOUT。
关于MapReduce作业中其他对象的名称(例如map函数,task,reduce函数和输入名称),名称必须是唯一的。
此外,名称不能与数据库中的现有对象(例如表,函数或视图)冲突。
FILE
指定MapReduce客户端计算机上的文件位置,以如下格式输出数据:/path/to/filename。
TABLE 指定数据库中用于输出数据的表的名称。 如果在运行MapReduce作业之前该表不存在,则将使用KEYS指定的分发策略创建该表。
KEYS
TABLE输出的可选项。
指定要用作Greenplum数据库分发键的列。
如果EXECUTE任务包含REDUCE定义,
则默认情况下REDUCE键将用作表分发键。
否则,表的第一列将用作分发键。
MODE
TABLE输出的可选项。
如果未指定,则默认为创建表(如果该表尚不存在),但如果表存在则输出错误。
声明APPEND将输出数据添加到现有表(前提是表模式与输出格式匹配),而不删除任何现有数据。
如果表存在,则声明REPLACE将删除该表,然后重新创建它。
如果不存在,APPEND和REPLACE都将创建一个新表。
MAP
必须。每个MAP函数采用以(key, value)对构造的数据,
处理每对,并生成零个或多个输出(key, value)对。
然后,Greenplum MapReduce框架从所有输出列表中收集具有相同密钥的所有对,并将它们组合在一起。
然后将此输出传递给REDUCE任务,
该任务由TRANSITION | CONSOLIDATE | FINALIZE函数组成。
有一个名为IDENTITY的预定义MAP函数,它返回的(key, value)对不变。
虽然(key, value)是默认参数,但您可以根据需要指定其他原型。
TRANSITION | CONSOLIDATE | FINALIZE
TRANSITION,CONSOLIDATE和FINALIZE都是REDUCE的组成部分。
需要TRANSITION函数。
CONSOLIDATE和FINALIZE函数是可选的。
默认情况下,所有将state作为其输入PARAMETERS的第一个,但也可以定义其他原型。
TRANSITION函数遍历给定键的每个值,并在state变量中累积值。
当在键的第一个值上调用转换函数时,state将设置为REDUCE作业的INITIALIZE指定的值(或数据类型的默认状态值)。
转换需要两个参数作为输入; 密钥减少的当前状态和下一个值,然后产生一个新state。
如果指定了CONSOLIDATE函数,则在segment级别执行TRANSITION处理,
然后在Greenplum互连上重新分配密钥以进行最终聚合(两阶段聚合)。
仅重新分配给定密钥的结果state值,从而导致更低的互连流量和更高的并行度。
CONSOLIDATE像TRANSITION一样处理,除了(state + value)=> state,
它是(state + state)=> state。
如果指定了FINALIZE函数,它将采用CONSOLIDATE(如果存在)或TRANSITION生成的最终state,
并在发出最终结果之前进行任何最终处理。
TRANSITION和CONSOLIDATE函数不能返回一组值。
如果需要REDUCE作业来返回一个集合,则需要FINALIZE将最终状态转换为一组输出值。
NAME 必须。函数的名称。关于此MapReduce作业中其他对象的名称(例如函数,任务,输入和输出名称),名称必须是唯一的。 您还可以指定Greenplum数据库内置函数的名称。 如果使用内置函数,请不要提供LANGUAGE或FUNCTION正文。
FUNCTION
可选。使用指定的LANGUAGE指定函数的完整主体。
如果未指定FUNCTION,
则使用与NAME对应的内置数据库函数。
LANGUAGE
使用FUNCTION时需要。指定用于解释函数的实现语言。
此版本具有对perl,python和C的语言支持。
如果调用内置数据库函数,则不应指定LANGUAGE。
LIBRARY
LANGUAGE为C时必需(不允许用于其他语言函数)。 要使用此属性,VERSION必须为1.0.0.2。 必须在运行MapReduce作业之前安装指定的库文件,并且该文件必须存在于所有Greenplum主机(master和segment)上的相同文件系统位置。
PARAMETERS
可选。函数输入参数。默认类型是text。
MAP default - key
text, value
text
TRANSITION default - state
text, value
text
CONSOLIDATE default -
state1 text, state2 text (必须具有相同数据类型的两个输入参数)
FINALIZE default - state
text (仅限单个参数)
RETURNS
可选。默认返回类型是text。
MAP default - key
text, value
text
TRANSITION default - state
text (仅限单个参数)
CONSOLIDATE default - state
text (仅限单个参数)
FINALIZE
default - value text
OPTIMIZE
该函数的可选优化参数:
STRICT - 函数不受NULL值的影响
IMMUTABLE - 函数将始终返回给定输入的相同值
MODE
可选。指定函数返回的行数。
MULTI - 每个输入记录返回0行或更多行。
函数的返回值必须是要返回的行数组,或者必须使用Python中的yield或Perl中的return_next将函数写为迭代器。
MULTI是MAP和FINALIZE函数的默认模式。
SINGLE - 每个输入记录只返回一行。
SINGLE是TRANSITION和CONSOLIDATE函数支持的唯一模式。
当与MAP和FINALIZE函数一起使用时,SINGLE模式可以提供适度的性能改进。
REDUCE
必须。REDUCE定义命名TRANSITION | CONSOLIDATE | FINALIZE函数,包括将(key,value)对缩减到最终结果集。
您还可以执行几个预定义的REDUCE作业,这些作业都在名为value的列上运行:
IDENTITY - 返回(键,值)对不变
SUM - 计算数值数据的总和
AVG - 计算数字数据的平均值
COUNT - 计算输入数据的计数
MIN - 计算数值数据的最小值
MAX - 计算数值数据的最大值
NAME
必须。这个REDUCE工作的名称。
关于此MapReduce作业中的其他对象的名称(函数,任务,输入和输出名称),名称必须是唯一的。
此外,名称不能与数据库中的现有对象(例如表,函数或视图)冲突。
TRANSITION
必须。TRANSITION函数名称。
CONSOLIDATE
可选。CONSOLIDATE函数名称。
FINALIZE
可选。FINALIZE函数名称。
INITIALIZE
text和float数据类型的可选项。
所有其他数据类型都需要。
文本的默认值为''。
float的默认值为0.0。
设置TRANSITION函数的初始state值。
KEYS
可选。默认为[key, *]。
使用多列缩减时,可能需要指定哪些列是键列,哪些列是值列。
默认情况下,未传递给TRANSITION函数的任何输入列都是键列,
名为key的列始终是键列,即使它传递给TRANSITION函数也是如此。
特殊指示符*表示未传递给TRANSITION函数的所有列。
如果该指示符不存在于键列表中,则丢弃任何不匹配的列。
TASK
可选。TASK在Greenplum MapReduce作业管道中定义了完整的端到端INPUT/MAP/REDUCE阶段。
它与EXECUTE类似,但不会立即执行。
可以被称为INPUT的任务对象进入进一步处理阶段。
NAME 必须。此任务的名称。 关于此MapReduce作业中其他对象的名称(例如map函数,reduce函数,输入和输出名称),名称必须是唯一的。 此外,名称不能与数据库中的现有对象(例如表,函数或视图)冲突。
SOURCE
INPUT或其他TASK的名称。
MAP
可选。MAP函数的名称。
如果未指定,则默认为IDENTITY。
REDUCE
可选。REDUCE函数的名称。
如果未指定,则默认为IDENTITY。
EXECUTE
必须。EXECUTE定义Greenplum MapReduce作业管道中的最终INPUT/MAP/REDUCE阶段。
RUN
SOURCE 必须。INPUT或TASK的名称。 TARGET
可选。OUTPUT的名称。默认值为STDOUT。
MAP
可选。MAP函数名称。
如果未指定,默认为IDENTITY。
REDUCE
可选。REDUCE函数的名称。默认为IDENTITY。
示例Greenplum MapReduce文档
# This example MapReduce job processes documents and looks for keywords in them.
# It takes two database tables as input:
# - documents (doc_id integer, url text, data text)
# - keywords (keyword_id integer, keyword text)#
# The documents data is searched for occurrences of keywords and returns results of
# url, data and keyword (a keyword can be multiple words, such as "high performance # computing")
%YAML 1.1
---
VERSION:1.0.0.1
# Connect to Greenplum Database using this database and role
DATABASE:webdata
USER:jsmith
# Begin definition section
DEFINE:
# Declare the input, which selects all columns and rows from the
# 'documents' and 'keywords' tables.
- INPUT:
NAME:doc
TABLE:documents
- INPUT:
NAME:kw
TABLE:keywords
# Define the map functions to extract terms from documents and keyword
# This example simply splits on white space, but it would be possible
# to make use of a python library like nltk (the natural language toolkit)
# to perform more complex tokenization and word stemming.
- MAP:
NAME:doc_map
LANGUAGE:python
FUNCTION:|
i = 0 # the index of a word within the document
terms = { }# a hash of terms and their indexes within the document
# Lower-case and split the text string on space
for term in data.lower().split():
i = i + 1# increment i (the index)
# Check for the term in the terms list:
# if stem word already exists, append the i value to the array entry
# corresponding to the term. This counts multiple occurrences of the word.
# If stem word does not exist, add it to the dictionary with position i.
# For example:
# data: "a computer is a machine that manipulates data"
# "a" [1, 4]
# "computer" [2]
# "machine" [3]
# …
if term in terms:
terms[term] += ','+str(i)
else:
terms[term] = str(i)
# Return multiple lines for each document. Each line consists of
# the doc_id, a term and the positions in the data where the term appeared.
# For example:
# (doc_id => 100, term => "a", [1,4]
# (doc_id => 100, term => "computer", [2]
# …
for term in terms:
yield([doc_id, term, terms[term]])
OPTIMIZE:STRICT IMMUTABLE
PARAMETERS:
- doc_id integer
- data text
RETURNS:
- doc_id integer
- term text
- positions text
# The map function for keywords is almost identical to the one for documents
# but it also counts of the number of terms in the keyword.
- MAP:
NAME:kw_map
LANGUAGE:python
FUNCTION:|
i = 0
terms = { }
for term in keyword.lower().split():
i = i + 1
if term in terms:
terms[term] += ','+str(i)
else:
terms[term] = str(i)
# output 4 values including i (the total count for term in terms):
yield([keyword_id, i, term, terms[term]])
OPTIMIZE:STRICT IMMUTABLE
PARAMETERS:
- keyword_id integer
- keyword text
RETURNS:
- keyword_id integer
- nterms integer
- term text
- positions text
# A TASK is an object that defines an entire INPUT/MAP/REDUCE stage
# within a Greenplum MapReduce pipeline. It is like EXECUTION, but it is
# executed only when called as input to other processing stages.
# Identify a task called 'doc_prep' which takes in the 'doc' INPUT defined earlier
# and runs the 'doc_map' MAP function which returns doc_id, term, [term_position]
- TASK:
NAME:doc_prep
SOURCE:doc
MAP:doc_map
# Identify a task called 'kw_prep' which takes in the 'kw' INPUT defined earlier
# and runs the kw_map MAP function which returns kw_id, term, [term_position]
- TASK:
NAME:kw_prep
SOURCE:kw
MAP:kw_map
# One advantage of Greenplum MapReduce is that MapReduce tasks can be
# used as input to SQL operations and SQL can be used to process a MapReduce task.
# This INPUT defines a SQL query that joins the output of the 'doc_prep'
# TASK to that of the 'kw_prep' TASK. Matching terms are output to the 'candidate'
# list (any keyword that shares at least one term with the document).
- INPUT:
NAME: term_join
QUERY: |
SELECT doc.doc_id, kw.keyword_id, kw.term, kw.nterms,
doc.positions as doc_positions,
kw.positions as kw_positions
FROM doc_prep doc INNER JOIN kw_prep kw ON (doc.term = kw.term)
# In Greenplum MapReduce, a REDUCE function is comprised of one or more functions.
# A REDUCE has an initial 'state' variable defined for each grouping key. that is
# A TRANSITION function adjusts the state for every value in a key grouping.
# If present, an optional CONSOLIDATE function combines multiple
# 'state' variables. This allows the TRANSITION function to be executed locally at
# the segment-level and only redistribute the accumulated 'state' over
# the network. If present, an optional FINALIZE function can be used to perform
# final computation on a state and emit one or more rows of output from the state.
#
# This REDUCE function is called 'term_reducer' with a TRANSITION function
# called 'term_transition' and a FINALIZE function called 'term_finalizer'
- REDUCE:
NAME:term_reducer
TRANSITION:term_transition
FINALIZE:term_finalizer
- TRANSITION:
NAME:term_transition
LANGUAGE:python
PARAMETERS:
- state text
- term text
- nterms integer
- doc_positions text
- kw_positions text
FUNCTION: |
# 'state' has an initial value of '' and is a colon delimited set
# of keyword positions. keyword positions are comma delimited sets of
# integers. For example, '1,3,2:4:'
# If there is an existing state, split it into the set of keyword positions
# otherwise construct a set of 'nterms' keyword positions - all empty
if state:
kw_split = state.split(':')
else:
kw_split = []
for i in range(0,nterms):
kw_split.append('')
# 'kw_positions' is a comma delimited field of integers indicating what
# position a single term occurs within a given keyword.
# Splitting based on ',' converts the string into a python list.
# add doc_positions for the current term
for kw_p in kw_positions.split(','):
kw_split[int(kw_p)-1] = doc_positions
# This section takes each element in the 'kw_split' array and strings
# them together placing a ':' in between each element from the array.
# For example: for the keyword "computer software computer hardware",
# the 'kw_split' array matched up to the document data of
# "in the business of computer software software engineers"
# would look like: ['5', '6,7', '5', '']
# and the outstate would look like: 5:6,7:5:
outstate = kw_split[0]
for s in kw_split[1:]:
outstate = outstate + ':' + s
return outstate
- FINALIZE:
NAME: term_finalizer
LANGUAGE: python
RETURNS:
- count integer
MODE:MULTI
FUNCTION:|
if not state:
return 0
kw_split = state.split(':')
# This function does the following:
# 1) Splits 'kw_split' on ':'
# for example, 1,5,7:2,8 creates '1,5,7' and '2,8'
# 2) For each group of positions in 'kw_split', splits the set on ','
# to create ['1','5','7'] from Set 0: 1,5,7 and
# eventually ['2', '8'] from Set 1: 2,8
# 3) Checks for empty strings
# 4) Adjusts the split sets by subtracting the position of the set
# in the 'kw_split' array
# ['1','5','7'] - 0 from each element = ['1','5','7']
# ['2', '8'] - 1 from each element = ['1', '7']
# 5) Resulting arrays after subtracting the offset in step 4 are
# intersected and their overlapping values kept:
# ['1','5','7'].intersect['1', '7'] = [1,7]
# 6) Determines the length of the intersection, which is the number of
# times that an entire keyword (with all its pieces) matches in the
# document data.
previous = None
for i in range(0,len(kw_split)):
isplit = kw_split[i].split(',')
if any(map(lambda(x): x == '', isplit)):
return 0
adjusted = set(map(lambda(x): int(x)-i, isplit))
if (previous):
previous = adjusted.intersection(previous)
else:
previous = adjusted
# return the final count
if previous:
return len(previous)
# Define the 'term_match' task which is then executed as part
# of the 'final_output' query. It takes the INPUT 'term_join' defined
# earlier and uses the REDUCE function 'term_reducer' defined earlier
- TASK:
NAME:term_match
SOURCE:term_join
REDUCE:term_reducer
- INPUT:
NAME:final_output
QUERY:|
SELECT doc.*, kw.*, tm.count
FROM documents doc, keywords kw, term_match tm
WHERE doc.doc_id = tm.doc_id
AND kw.keyword_id = tm.keyword_id
AND tm.count > 0
# Execute this MapReduce job and send output to STDOUT
EXECUTE:
- RUN:
SOURCE:final_output
TARGET:STDOUT
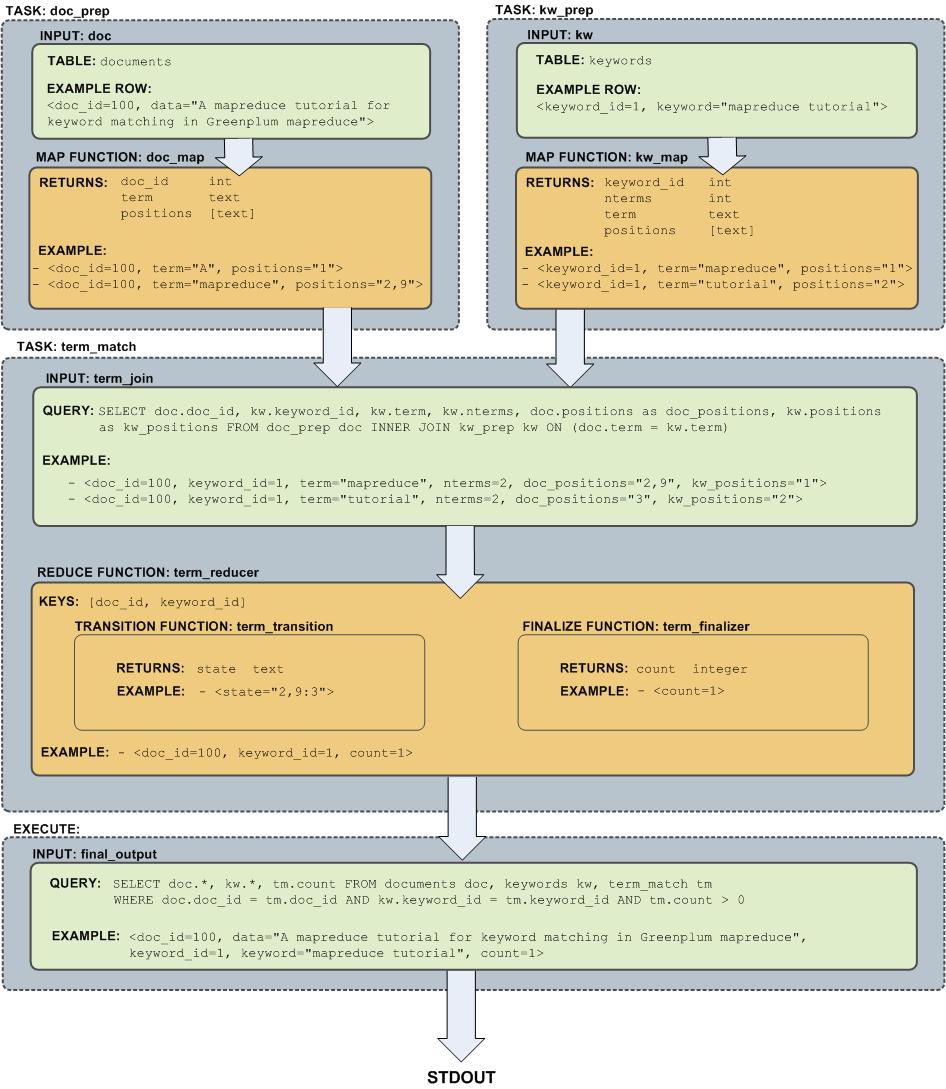
MapReduce示例的流程图
下图显示了示例中定义的MapReduce作业的作业流程: